In today’s digital age, extracting information from documents efficiently and accurately has become a necessity for businesses and individuals alike. Fortunately, there are several services and tools available to simplify this process. In this article, I will compare two popular options: Amazon Textract and Camelot. The purpose of this demonstration is to showcase the differences in the output generated by these services, helping me understand their capabilities and make informed decisions without the need for signing up or installing packages.
Test-1: Extract single and large table.
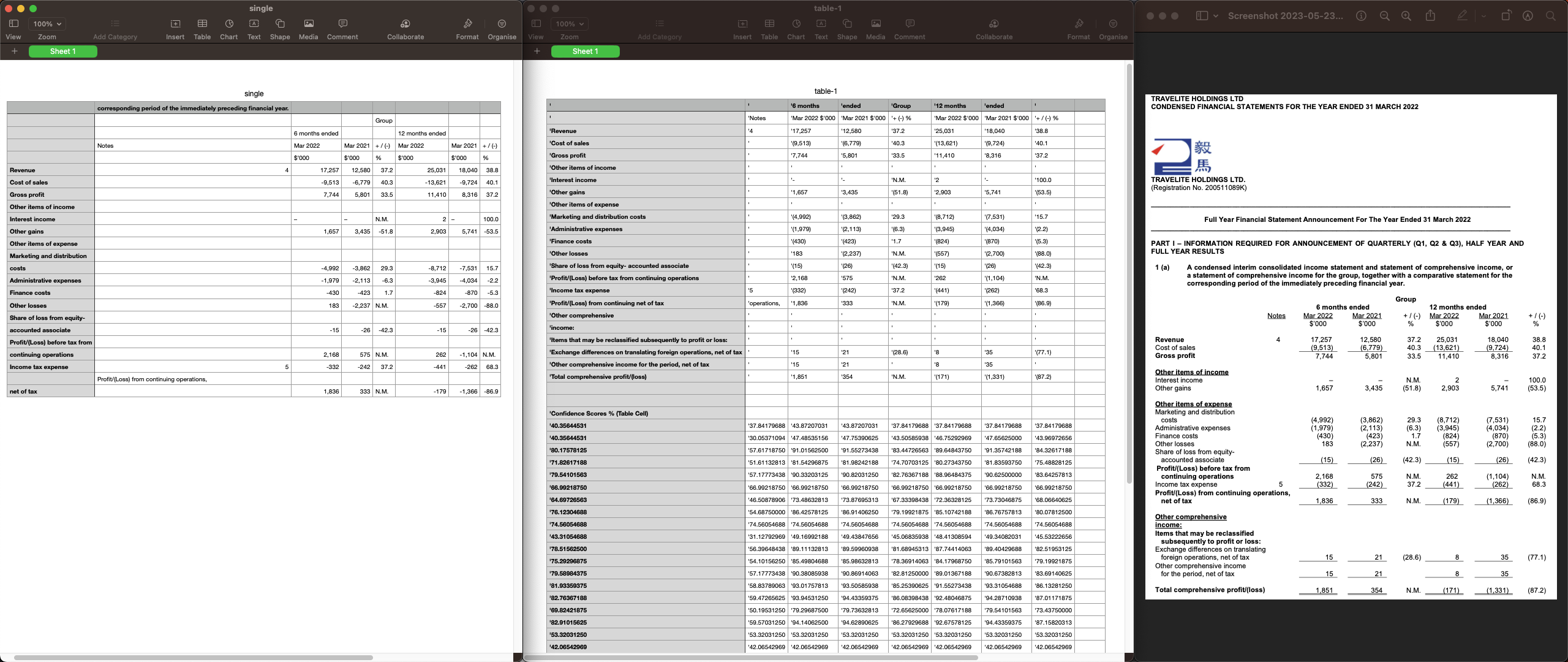
Refer to the image above, left-hand-side is the Camelot output saved as csv file; middle is the AWS textract output; right-hand-side is the input pdf page.
In this case, i think AWS produced better output for me:
- (1) Capture the entire table;
- (2) Long line item are captured and grouped correctly (i.e., see the third underlined section title - Other comphrensions Income);
- (3) Negative numbers are parsed as the original format (i.e., output as (9513) instead of -9513);
- (4) Column header texts are grouped together (i.e., Mar 2022 $’000’).
The third point is not necessarily an issue but personally i prefer original format.
Test-2: Extract multi-tables.

Similarly, camelot output is on the left hand side whereas AWS textract output is the middle one.
In this test case, AWS produced better result again:
- (1) Long line item are grouped as one cell (look at last row of the first table.);
- (2) Captured the second table at the bottom of the page. However, one noticable mistake from AWS
is that the
Notecolumn in the second table is merged into the left-hand-side row-header column.
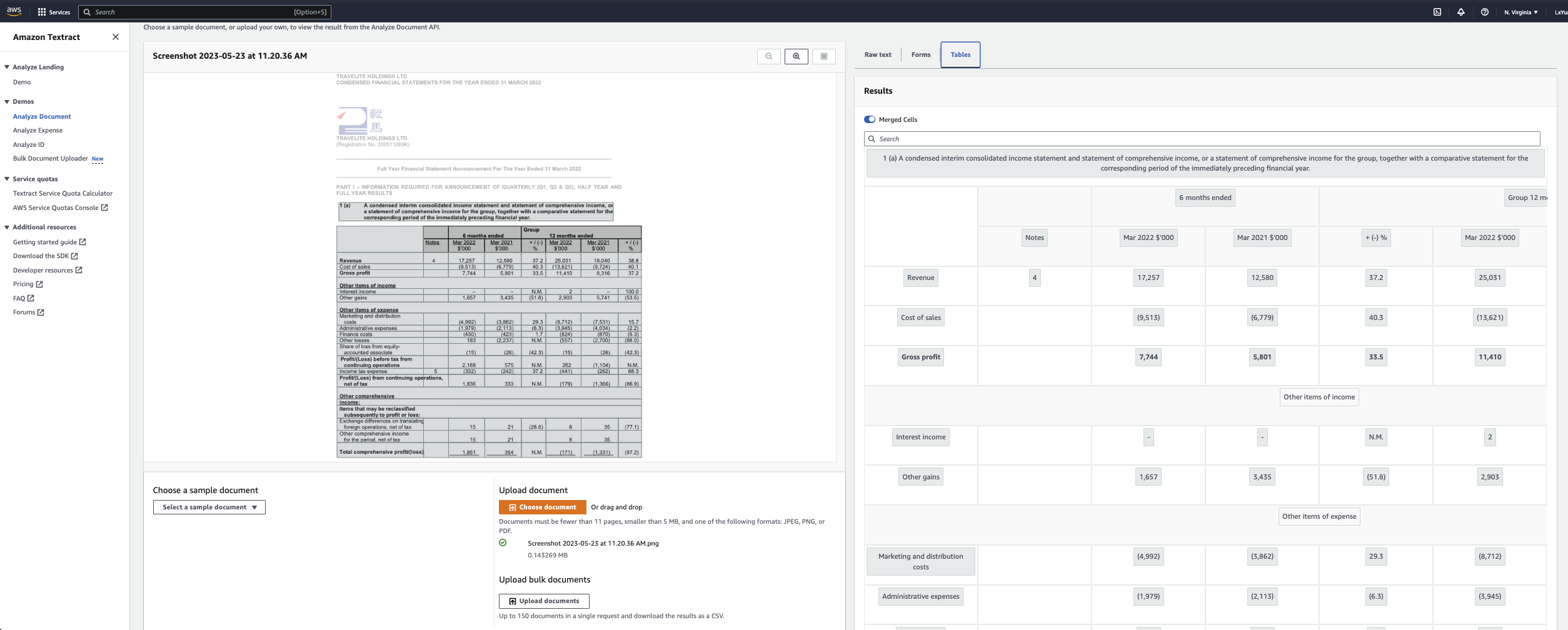
Image below is the screenshot of AWS textract UI.
Sample Camelot code
# installation
!pip install "camelot-py[base]"
# fix: PyPDF2.errors.DeprecationError
# source: https://github.com/camelot-dev/camelot/issues/339
!pip install 'PyPDF2<3.0'
# fix: RuntimeError: Please make sure that Ghostscript is installed
# source: https://github.com/atlanhq/camelot/issues/184
!apt install ghostscript python3-tk
from ctypes.util import find_library
find_library("gs")
# fix: DependencyError: PyCryptodome is required for AES algorithm
!pip install pycryptodome==3.15.0
import camelot
# Test-1: single-table
table = camelot.read_pdf(
"/content/SG220527OTHRMX7S-travelite_holdings_ltd.pdf",
pages='1',
flavor='stream'
)
# save as csv file
table[0].to_csv("single.csv")
# Test-2: multi-tables
table = camelot.read_pdf(
"/content/SG220805OTHR7ZPG_Sembcorp Industries Ltd_20220805072353_00_FS_2Q_20220630.pdf",
pages='6',
flavor='stream'
)
# save as csv file
table[0].to_csv("multi.csv")
Related: