There’s been a lot of buzz lately about LLM and how it can be used for different applications with OpenAI. In this article, we’ll give you a quick rundown on how to set up a cool DocQA application using LangChain and OpenAI, and we’ll even show you some examples of the query results. So, let’s dive in!
The high-level idea is to:
- Load PDFs from a directory.
- Read all the texts and split them into chunks.
- Convert each chunk into an embedding.
- Save the embedding into ChromaDB.
- Convert the user’s query input into an embedding.
- Find the most relevant chunk based on embedding similarity.
- Output the selected chunk.
The code is pretty simple:
import os
from langchain.document_loaders import PyPDFDirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
os.environ["OPENAI_API_KEY"] = "<your-openai-api-key>"
loader = PyPDFDirectoryLoader("/content/my_pdf_dir")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)
texts = text_splitter.split_documents(docs)
persist_directory = "./my_pdf_db"
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=texts,
embedding=embeddings,
persist_directory=persist_directory)
vectordb.persist()
retriever = vectordb.as_retriever()
llm = ChatOpenAI(model_name='gpt-3.5-turbo') #gpt-4 or gpt-3.5-turbo
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
while True:
user_input = input("Enter a query: ")
if user_input == "exit":
break
query = f"###Prompt {user_input}"
try:
llm_response = qa(query)
print(llm_response["result"])
print("\n")
except Exception as err:
print('Exception occurred. Please try again', str(err))
Below is the terminal output:
>>>
Enter a query: Refer to Dragon Group International financial report, what is the reported "Cash and cash equivalent" amount as of 30 September 2022?
I'm sorry, I cannot find the reported "Cash and cash equivalent" amount as of 30 September 2022 in the given context. The condensed consolidated balance sheet available on page 20 provides some financial information, but it does not include this specific figure.
Enter a query: Refer to the Dragon Group financial report, where is the company located?
According to the financial report, Dragon Group International Limited is domiciled and incorporated in Singapore.
Enter a query: Has the company HS Optimus Holdings Limited proposed any interim dividend for the periods ending on September 30, 2022, and September 30, 2021, based on the given context
According to the given context, there is no proposal or declaration of any dividend by HS Optimus Holdings Limited for the six months ended 30 September 2022 or the corresponding period of the immediately preceding financial year.
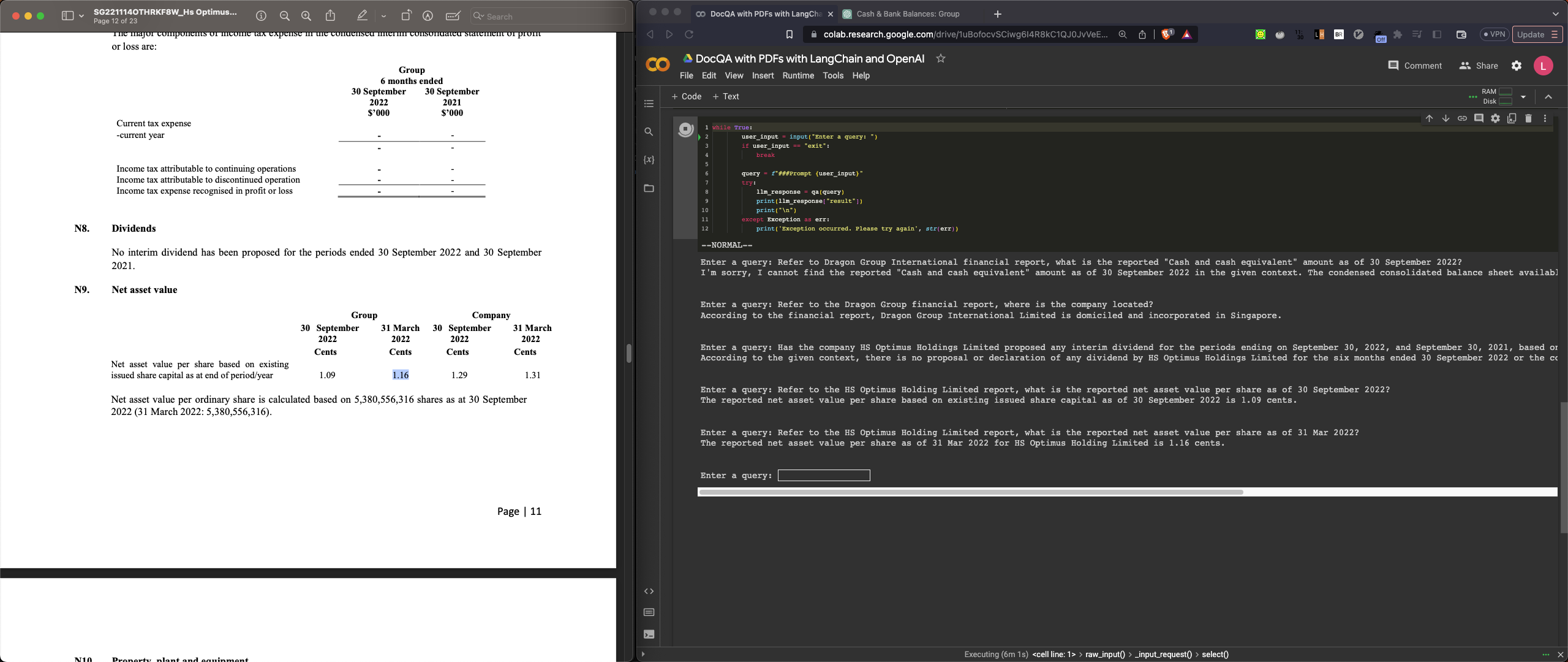
Enter a query: Refer to the HS Optimus Holding Limited report, what is the reported net asset value per share as of 30 September 2022?
The reported net asset value per share based on existing issued share capital as of 30 September 2022 is 1.09 cents.
Enter a query: Refer to the HS Optimus Holding Limited report, what is the reported net asset value per share as of 31 Mar 2022?
The reported net asset value per share as of 31 Mar 2022 for HS Optimus Holding Limited is 1.16 cents.
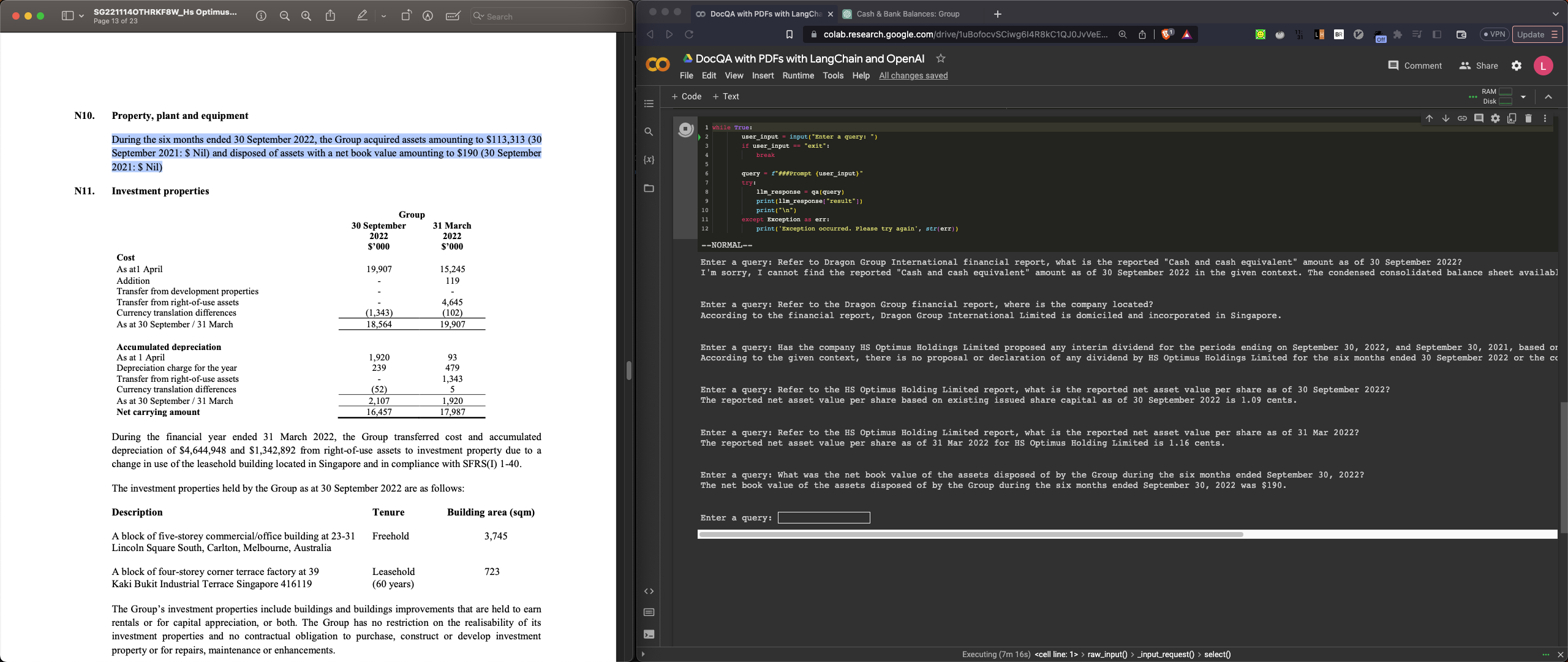
Enter a query: What was the net book value of the assets disposed of by the Group during the six months ended September 30, 2022?
The net book value of the assets disposed of by the Group during the six months ended September 30, 2022 was $190.
Below are screenshot images that include the asnwer from the target page:
Q1-review: Unable to extract or answer the correct value from the Cash-flow
table. I believe it is because the texts in the table are jumbled together.
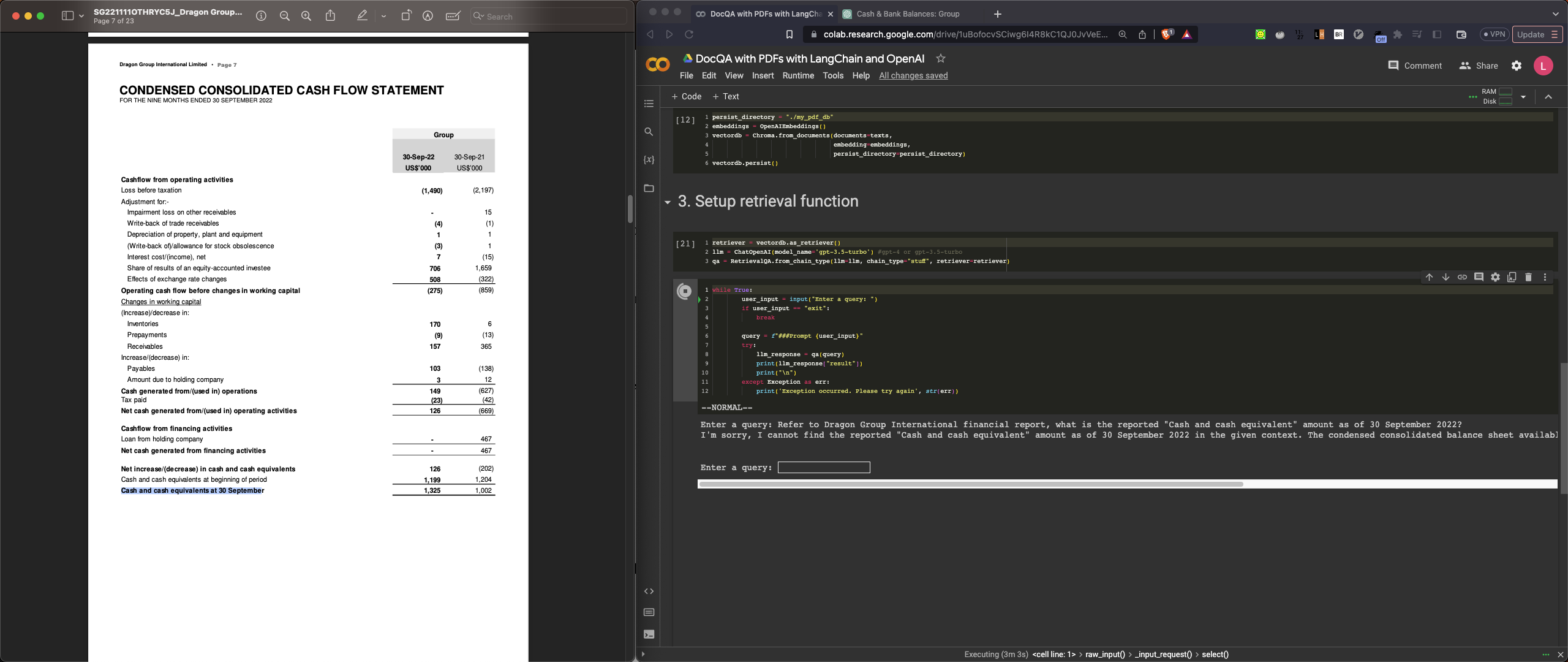
Q2-review: Model answered the company is domiciled and incorporated in
Singapore, which is correct. However, I’m expecting the model give me a full
address as answer.
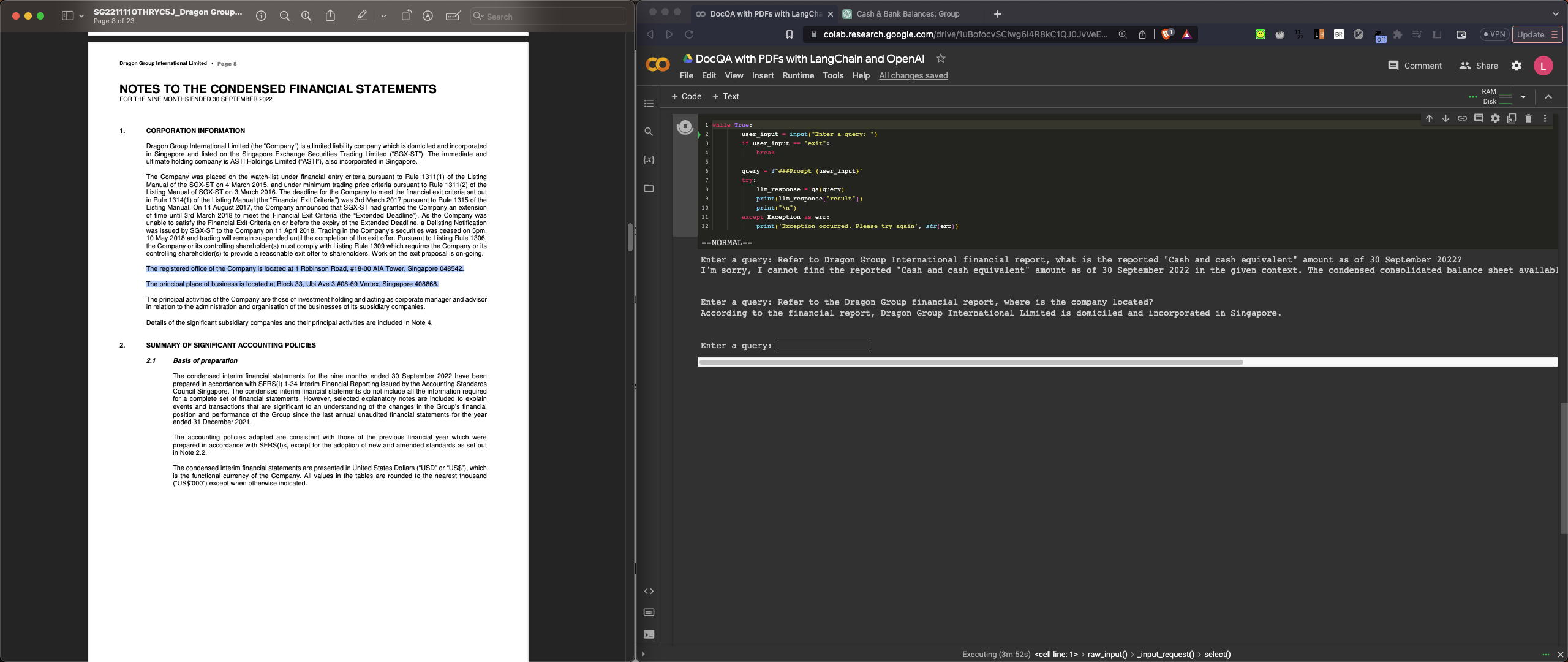
Q3-review: We got the correct answer this time. There is no dividend for the periods ended 30-Sep-2022 and 30-Sep-2021.
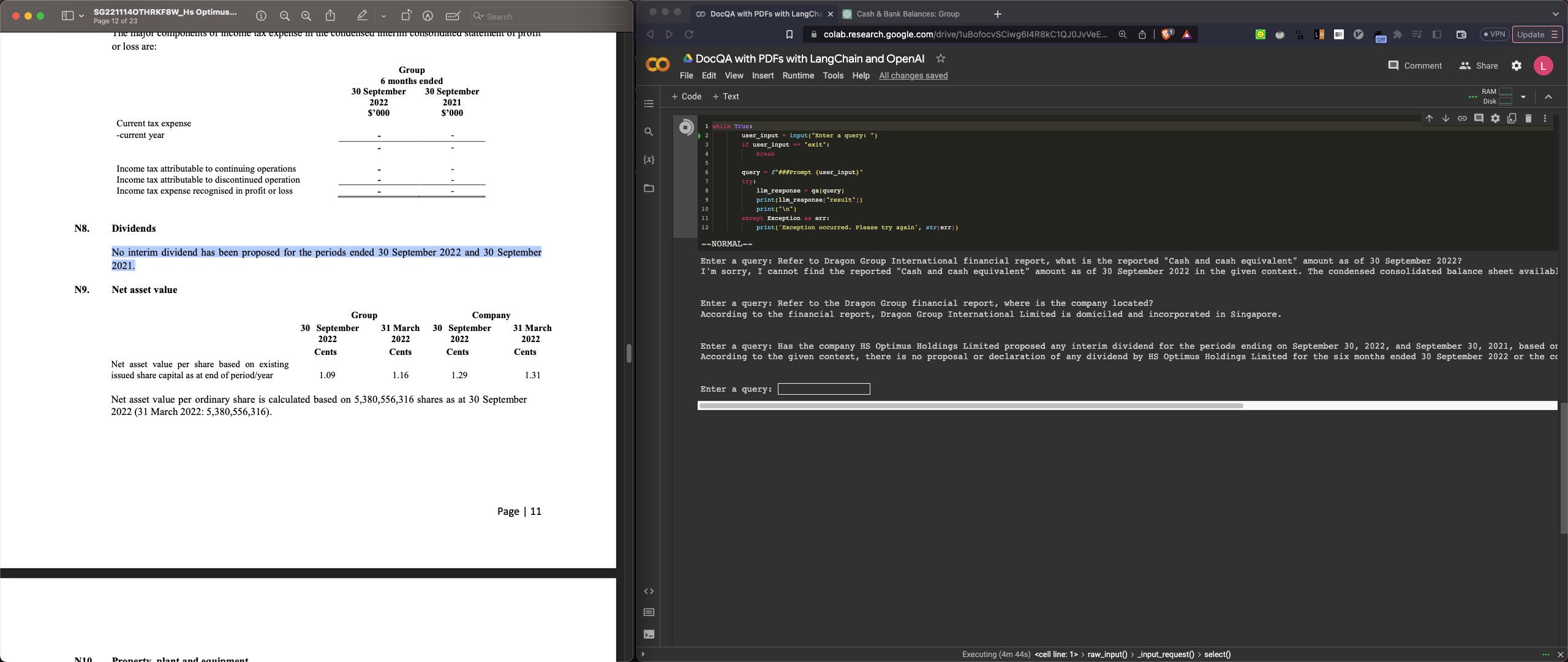
Q4-review: Got the correct value 1.09 from the table.
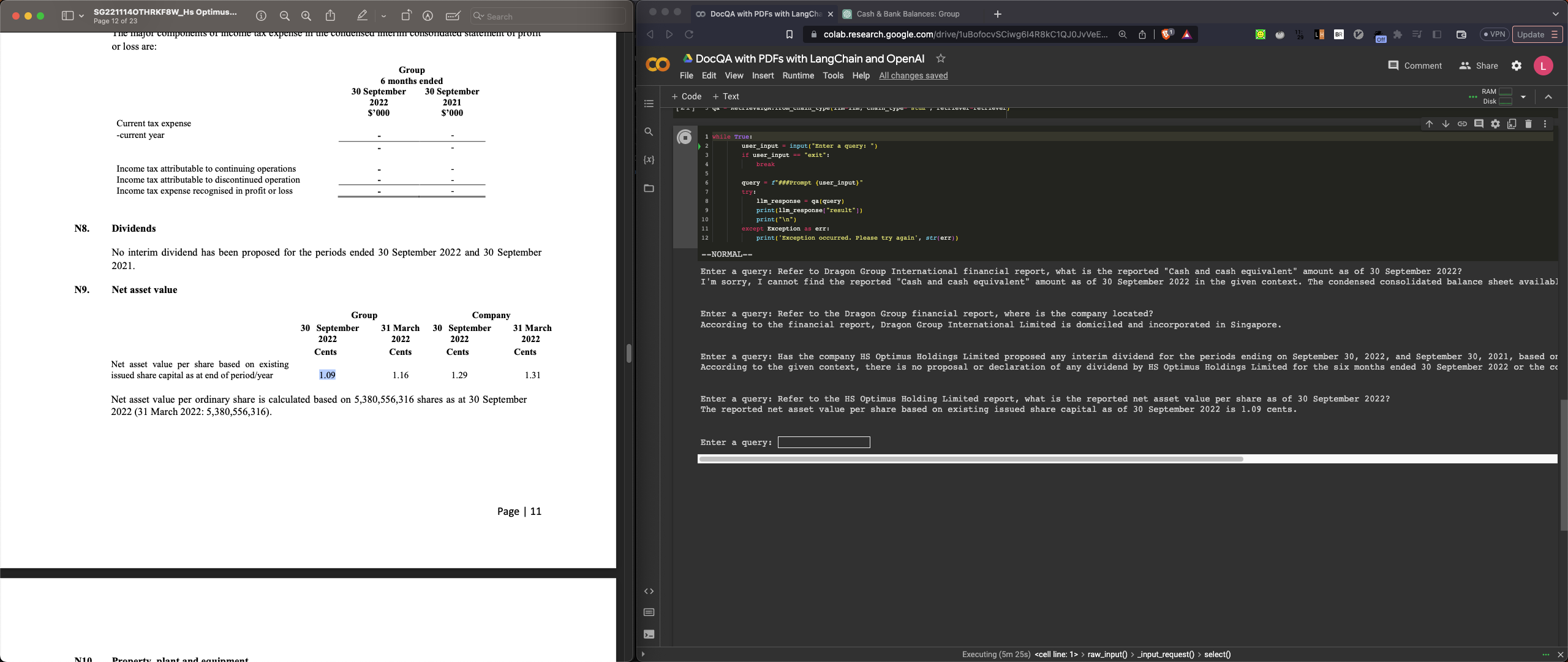
Q5-review: Got the correct value 1.16 from the table. I think it is just lucky
as we all know the text from table are actually jumbled together and is not a
proper sentence like the Q3 dividend case.
Q6-review: The model answered it correctly and personally I like this
question-answer pair the most as the model rephrased it instead of directly
extracting or copying the paragraph from the page.
Related: