TLDR: Try the finetuned DistilGPT-2 model here :smile:
I have some free time this weekend and I always wanted to fine tune a language model to gain some hands-on experience. Huge thanks to Huggingface for making everything so accessible and easy.
In this blog, i share things that i learnt from this fun project and break down the idea of fine-tuning language model into 3 parts:
- Data
- Model
- Trainer
Data
In this example, we are using wikitext dataset. The WikiText language modeling dataset is a collection of over 100 million tokens extracted from the set of verified Good and Featured articles on Wikipedia.
Dataset Preview:
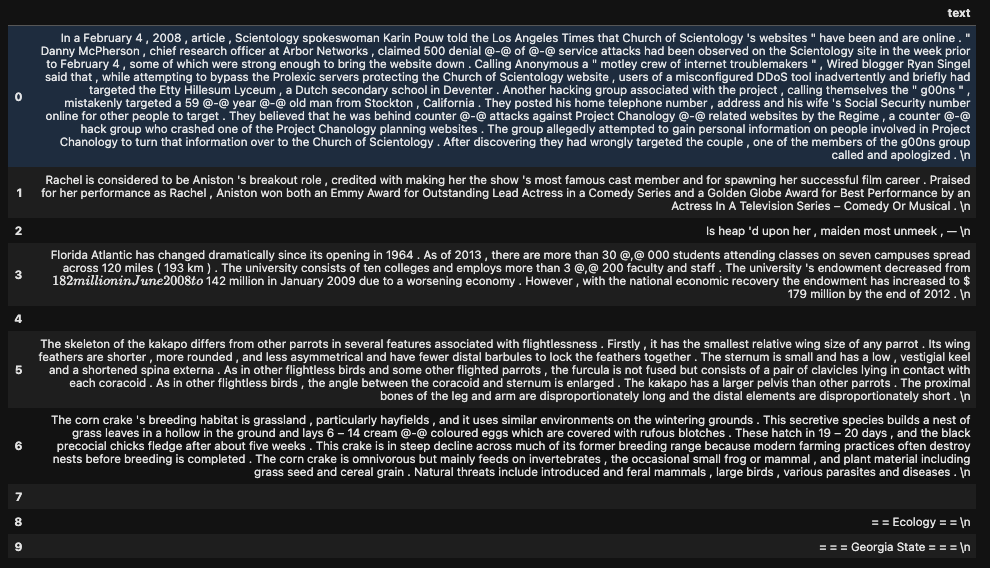
As we can see, some of the texts are a full paragraph of a Wikipedia article
while others are just titles or empty lines. The first step is to tokenize them
and then split them in small chunks of a certain block_size using the following
code:
from transformers import AutoTokenizer
def tokenize_function(examples):
return tokenizer(examples["text"])
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
model_checkpoint = "distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"])
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
batch_size=1000,
num_proc=4,
)
We can refer to the dummy example below to understand how the group_texts()
function works. The idea is to concatenate input_ids of all examples (i.e, make it a long list of int) together
and split them into small chunks (i.e., make it a list of list of int).
examples = {
"input_ids": [
[1,1,1],
[2,2,2],
[],
[4,4,4]
]
}
examples
>>> {'input_ids': [[1, 1, 1], [2, 2, 2], [], [4, 4, 4]]}
block_size = 2
results = group_texts(examples)
>>>
# concat_examples = {
# 'input_ids': [1, 1, 1, 2, 2, 2, 4, 4, 4]
# }
{'input_ids': [[1, 1], [1, 2], [2, 2], [4, 4]],
'labels': [[1, 1], [1, 2], [2, 2], [4, 4]]}
The remainder 4 is excluded at the end. You may also notice that we duplicate the input_ids for the labels. This is because HF model class will automatically apply the shifting to right, so we don’t need to any thing manually. One can refer to the official pytorch code implemention to learn more about that.
Model
For the model part, we just need to load the pretrained DistilGPT-2 model and define training arguments.
from transformers import AutoModelForCausalLM
from transformers import Trainer, TrainingArguments
model = AutoModelForCausalLM.from_pretrained(model_checkpoint)
model_name = model_checkpoint.split("/")[-1]
training_args = TrainingArguments(
f"{model_name}-finetuned-wikitext2",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
weight_decay=0.01,
num_train_epochs=6,
push_to_hub=True,
)
As we wanted to push to the final trained model to HF model hub, we set the argument push_to_hub=True and set the output_dir argument (i.e, the first one positional argument in TrainingArguments()). If things went well, we could download and try our model using namespace:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("lxyuan/distilgpt2-finetuned-wikitext2")
model = AutoModelForCausalLM.from_pretrained("lxyuan/distilgpt2-finetuned-wikitext2")
Trainer
We then can start training them as usual. We just need to run 2 more commands to push the model and tokenizer to our repo: distilgpt2-finetuned-wikitext2.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
)
trainer.train()
trainer.push_to_hub()
tokenizer.push_to_hub("distilgpt2-finetuned-wikitext2")
Inferecing example
One of the easiet way to try the model is to use pipeline(), as follows:
from transformers import pipeline
generator = pipeline(model="lxyuan/distilgpt2-finetuned-wikitext2")
generator("Lion King is", pad_token_id=generator.tokenizer.eos_token_id, max_new_tokens=50, num_return_sequences=2)
>>>
[{'generated_text': 'Lion King is the only king of the two lands currently controlled by the emperor. King Henry II has since ruled through the Middle Ages, most recently after his death. Queen Edward I of England was assassinated in 1765. Edward II died in 1666. \n'},
{'generated_text': 'Lion King is a playable version of the main story arc for The New Adventures of Magic. An updated version features two characters on a different character : the Dark Knight ( Shadow Knight ) and the Knights of the Temple of the Shadow ( Z @-@ Knight ).'}]
Extra: