I have been occupied with work for the past month, and I finally have some time to delve into new things. I’m not sure about you all, but I increasingly find myself relying on ChatGPT for coding tasks. It’s been useful for simple tasks like creating a Python regex to extract US phone numbers from a string, as well as more complex tasks like writing a FastAPI script that utilizes the Hugging Face pipeline for text summarization. So far, it has been working well for me. However, it’s important to remember that everything we ask or write to ChatGPT is captured by OpenAI, so we should refrain from sharing any company intellectual property, such as code or config files, with them, regardless of how unrelated or trivial it may seem.
In this post, we will explore how to run Replit-v2-CodeInstruct-3B, which is a Code Completion LLM, on your local CPU. This model can serve as a coding assistant for work or learning, helping to enhance your productivity. However, please note that when running inference on the Replit CodeInstruct model using a ggml quantized model on a CPU, the performance may not be optimal. The advantages of this model include decent speed and privacy, while the downside is its subpar performance. For more serious work, I still recommend using ChatGPT.
Setup environment
First, we need to set up the environment and download the model for inference. You can follow the provided commands:
$ git clone https://github.com/abacaj/replit-3B-inference.git
$ python -m venv env && source env/bin/activate
$ pip install -r requirements.txt
$ python download_model.py
$ python inference.py
Now we are ready. Let start with one simple and one difficult test cases and compare this model and chatgpt side by side.
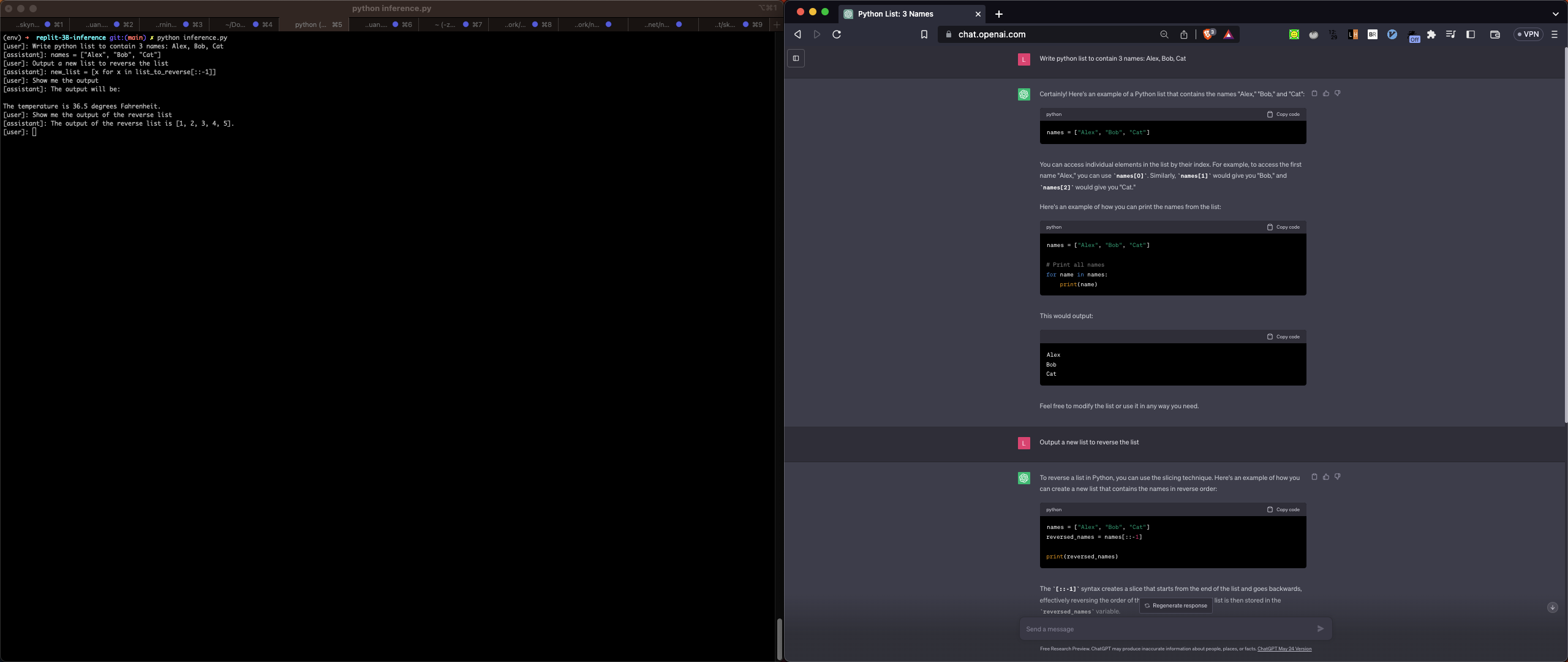
Simple test case: To create and reverse python list
Both models are capable of creating a new Python list, but Replit failed to reverse the list in a Pythonic way and assign it to a new variable. When I requested the output, it started giving me nonsensical results :(
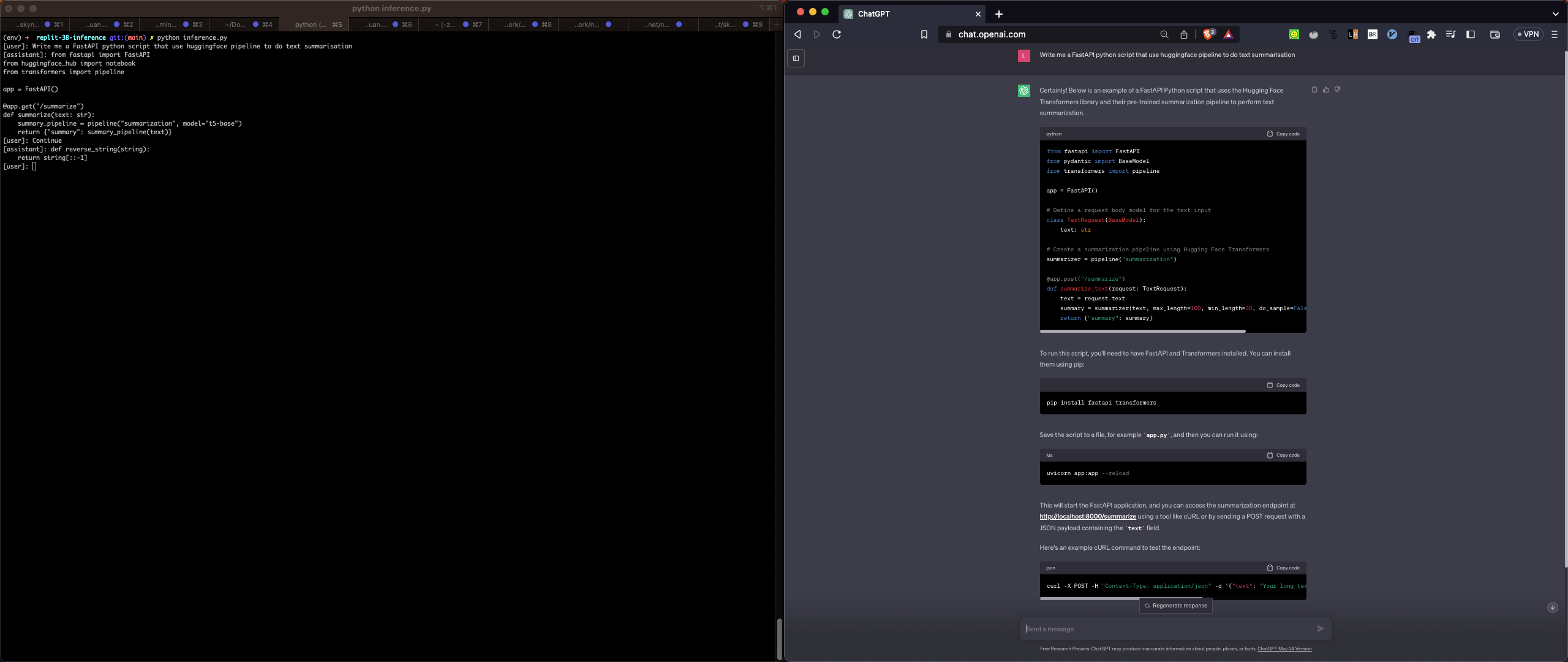
Difficult test case: To create FastAPI script for summarisation
This is a slightly more challenging case. It seems like Replit only completed about 20% of the code, whereas ChatGPT provided almost complete results, including the usage commands.
Of course, it is not an apple to apple comparison. If you wish to explore more on the Replit model, feel free to adjust the temperature, top_k, top_p configuration:
(env) ➜ replit-3B-inference git:(main) ✗ tail -25 inference.py
)
generation_config = GenerationConfig(
temperature=0.2,
top_k=50,
top_p=0.9,
repetition_penalty=1.0,
max_new_tokens=512, # adjust as needed
seed=42,
reset=True, # reset history (cache)
stream=True, # streaming per word/token
threads=int(os.cpu_count() / 6), # adjust for your CPU
stop=["<|endoftext|>"],
)
user_prefix = "[user]: "
assistant_prefix = f"[assistant]:"
while True:
user_prompt = input(user_prefix)
generator = generate(llm, generation_config, user_prompt.strip())
print(assistant_prefix, end=" ", flush=True)
for word in generator:
print(word, end="", flush=True)
print("")
Related: